- Updated:

robots.txt settings
To manage robots.txt settings, go to Configuration → Settings → General settings.
This page enables multi-store configuration; it means that the same settings can be defined for all stores or differ from store to store. If you want to manage settings for a certain store, choose its name from the multi-store configuration dropdown list and select all the checkboxes needed on the left to set custom values for them. For further details, refer to Multi-store.
robots.txt
A robots.txt file tells search engine crawlers which URLs the crawler can access on your site. This is used mainly to avoid overloading your site with requests; it is not a mechanism for keeping a web page out of Google. To keep a web page out of Google, block indexing with noindex or password-protect the page.
Define the robots.txt settings as follows:
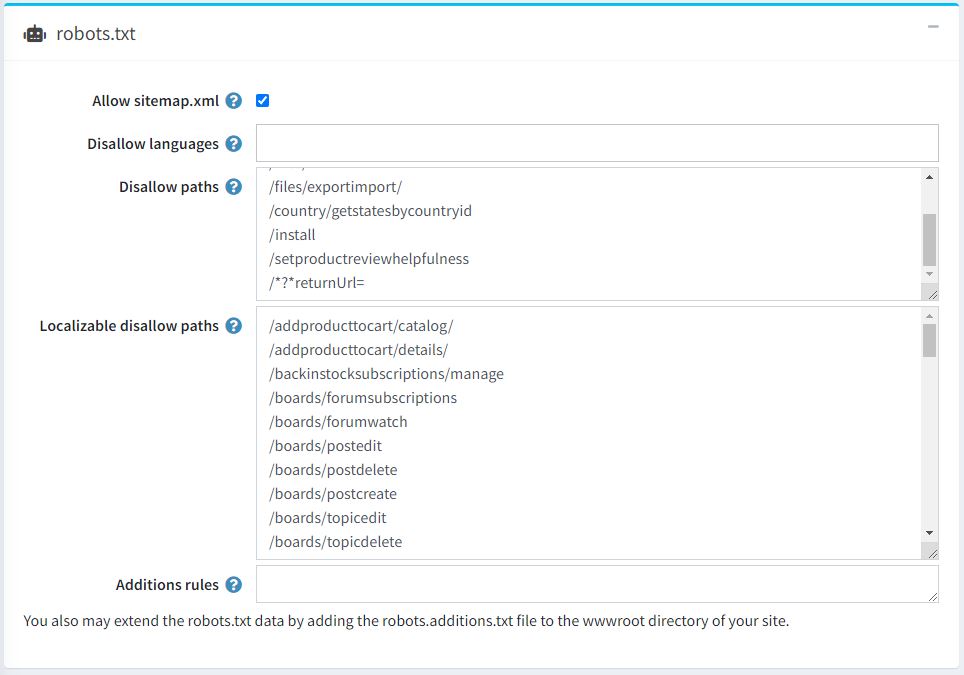
- Allow sitemap.xml - Check to allow robots to access the sitemap.xml file.
- Disallow languages - The list of languages to disallow. Leave this field blank if you don't want to restrict certain languages to robots.
- Disallow paths - The list of paths to disallow.
- Localizable disallow paths - The list of localizable paths to disallow.
- Additions rules - Enter additional rules for the robots.txt file. Rules are instructions for crawlers about which parts of your site they can crawl. Read this page about Google's interpretation of the robots.txt specification for the complete description of each rule.
Note
You also may extend the robots.txt data by adding the robots.additions.txt file to the wwwroot directory of your site.